第4回 Pythonの基礎2#
![]()
第3回では、数値や文字列といった基本的なデータの扱い方を学んだ。 プログラミングを工作に例えると、これらデータは材料にあたる。 一方で、工作における道具にあたるものが関数やメソッドである。 今回はデータについてさらに詳しく学び、関数やメソッドについても学ぶ。
データと関数#
Pythonには数値や文字列の他にもいろいろな種類のデータがある。こうした種類の違いのことをデータの型(type)と言う。 データ型には、整数型(int)、浮動小数点数型(float)、文字列型(str)、リスト型(list)、ブール型(bool)などがある。
データ型を調べるには type() という関数を使う。関数とは何かについて説明する前に、まずは使ってみよう。
type(3)
int
type(3.14)
float
type("text")
str
上から順に 3 は整数型、3.14 は浮動小数点数型、"text" は文字列型という結果になった。
ここで使った type() は、データを受け取り、そのデータ型を調べて結果を返した。
このようにデータを受け取って、何らかの処理を行った上で、必要に応じて結果を返すものを関数という。
関数は引数という変数を通じてデータを受け取り、必要に応じて戻り値を返す。
例えば type("text") というコードでは、type() 関数は "text" というデータを引数として受け取り、str という型を戻り値として返している。
関数によっては引数を複数持つこともあり、その場合はデータを , で区切って渡す。関数の使い方を一般的な形で図に表すと、次のようになる。
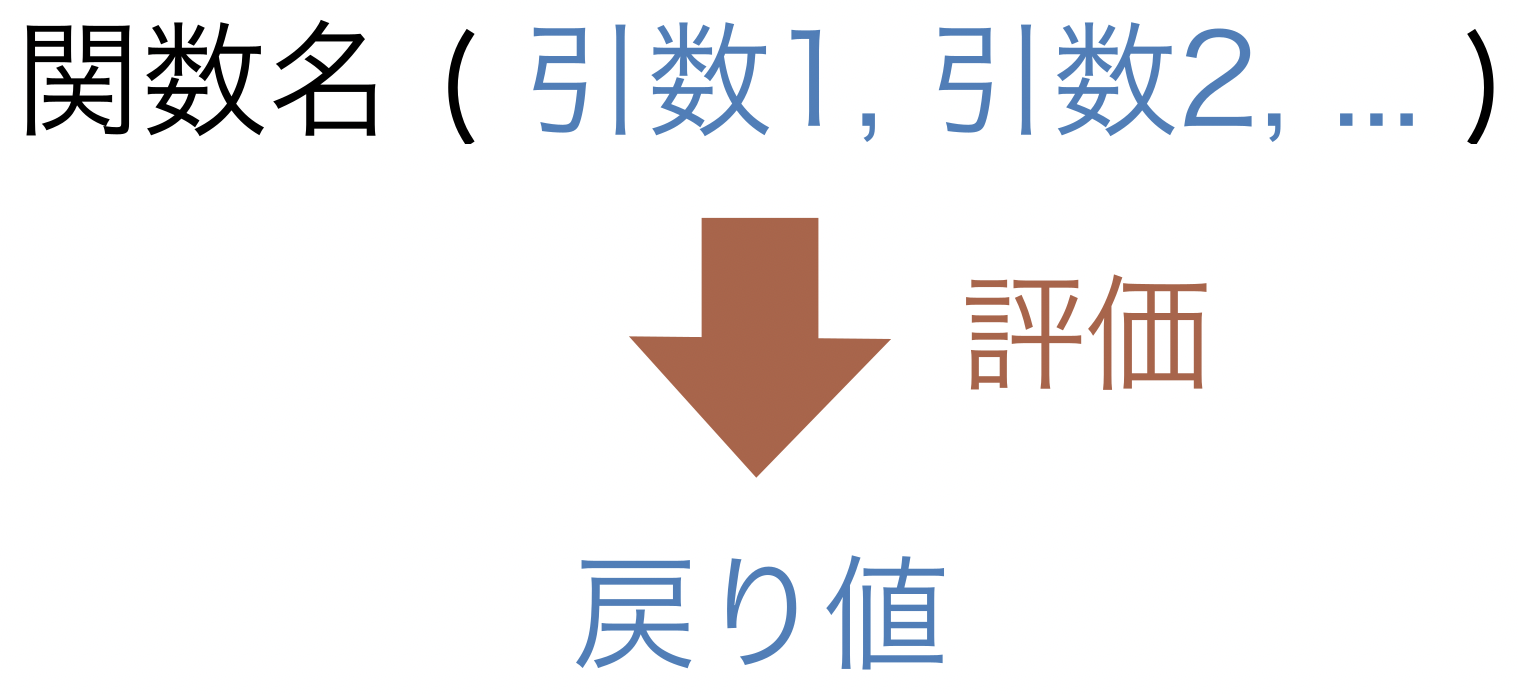
Fig. 5 関数の使い方#
実は前回の講義でも説明なしに print() という関数を使っていた。print() は複数のデータを受け取り、戻り値を返さない関数である。
print("text1", "text2", 3)
text1 text2 3
複数のデータを渡すと、空白を間に挟んで出力する。
少し細かい話になるが、この出力は print() 関数の戻り値ではなく、出力するという処理を行ったと考えるのが正しい。
次のコードは、戻り値に関して type() 関数と print() 関数を比較したものである。
a = type("text")
a
str
b = print("text")
text
b
ノートブック環境ではセルの最終行を評価した値が自動的に表示されるが、a = type("text") のような代入文については評価しても出力されるものはない。
一方で、b = print("text") を実行したときに text と表示されたのはノートブックの機能によるものではなく print() 関数の処理によるものである。
また変数 a には type() 関数の戻り値 str が代入され、変数 b には値がないことがわかる。
整数型と浮動小数点数型#
それでは先ほど紹介したデータ型を順に見ていこう。 まず整数型(int)は、名前のとおり整数を表すデータ型である。 一方、浮動小数点数型(float)は、小数を一定の精度で表現したものである。
例えば、3 は整数型のデータとして扱われるが、3.0 は浮動小数点数型のデータとして扱われる。
以後、例えば整数型のデータのことを単に整数と呼ぶ。
type(3)
int
type(3.0)
float
浮動小数点数が、小数を完璧な精度で表現していないという点は重要である。これは第2回の講義で説明したとおり、小数も内部では2進数で表現されており、例えば 1/3 = 0.3333...のように無限に桁の続く小数を、有限のビット数では正確には表現できないためである。
次の結果は驚きかもしれない。
0.1 * 3
0.30000000000000004
わずかな差ではあるが、0.1 * 3 はなんと 0.3 にならない。
これは内部の小数の表現方法に起因する誤差によるものである。
このように小数の計算では、わずかな誤差が生じうることを念頭におく必要がある。
文字列型#
文字列型(str)は、名前のとおり文字を表すデータ型である。前回学んだとおり、両端をシングルクォーテーション( ‘ )またはダブルクォーテーション( ” )で囲うと、文字列型のデータとして扱われる。
type("Hello")
str
type("2.0")
str
"2.0" は文字列であり、数値とは明確に区別される。
3 + "2.0"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/p0/0zrw9jsj03v3vlszs8v3m2p40000gn/T/ipykernel_74814/2203997697.py in <module>
----> 1 3 + "2.0"
TypeError: unsupported operand type(s) for +: 'int' and 'str'
エラーメッセージにある通り、整数と文字列を足すことはできない。
この計算をエラーなく実行するためには、両者のデータ型を揃えることが必要である。
文字列を数値に変換するには int() または float() 関数を、数値を文字列に変換するには str() 関数を用いる。
結果を予想しながら、次のコードを実行してみよう。
3 + float("2.0")
5.0
str(3) + "2.0"
'32.0'
リスト型#
リスト型(list)は、複数のデータをまとめるためのデータ型である。データを , で区切り、両端を [] で囲うことで定義する。
x = [1, 2, 3, "four", 5.6]
type(x)
list
リストの各要素にはインデックスと呼ばれる整数を使ってアクセスする。 左から読むか、右から読むかに応じて2種類のアクセス方法がある。 次の図に各要素とインデックスの関係を表す。
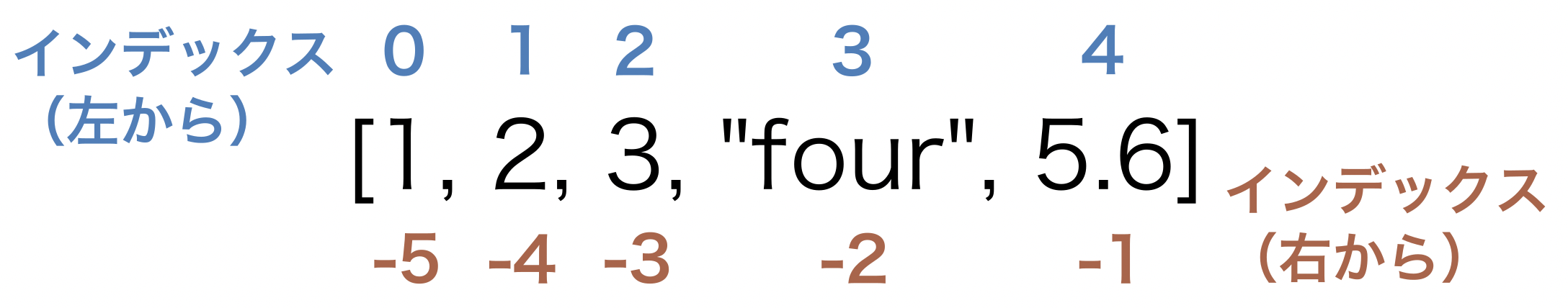
Fig. 6 インデックス#
例えば "four" という要素には次のようにアクセスすることができる。
x[3]
'four'
x[-2]
'four'
基本的には左読みのインデックスが使われる。一方、右端の要素にアクセスするときなど、右から数えるのが自然な場合には右読みのインデックスが使われる。 左読みのインデックスは、0始まりであることに気をつけよう。
リストの要素数は len() 関数により調べることができる。
len(x)
5
ブール型#
ブール型(bool)は True もしくは False の2種類の真偽値をとり、それぞれ真か偽かを表すデータ型である。
type(True)
bool
ブール型は、主に第5回の講義で学ぶ条件分岐のために使われる。例えば、次の比較演算子を使うことで数値の大小関係を判定することができるが、その結果はブール型で表される。
比較演算子 |
意味 |
|---|---|
|
(左の値は右の値より)大きい |
|
以上 |
|
未満 |
|
以下 |
|
等しい |
|
等しくない |
2つの値が等しいかどうかは = ではなく == という記法を使うことに注意する。
実際にいくつかの例を見てみよう。
10 > 1
True
10 == 1
False
10 != 1
True
3 == 3.0
True
0.1 * 3 == 0.3
False
最後の結果は、浮動小数点数のもつ誤差によるものである(0.1 * 3 が 0.3 と等しいかどうか、誤差も加味して比較を行うにはどうしたら良いだろうか?)
もちろんブール型のデータも、変数に代入することができる。
a = (10 == 1)
a
False
ブール型の現れる他の例として、in演算子がある。これは集合を表すデータ型の要素に、とあるデータが含まれるかどうかを判定する。
例えば、B をリストとして A in B と書くとき、データ A が B に含まれるかどうかを判定して、真偽値を返す。
使用例を以下に示す。
2 in [1, 3, 5, 7, 9]
False
4 in [2, 4, 6, 8]
True
オブジェクトとメソッド#
関数の中には、それぞれのデータ型に専属の関数も存在する。
そのような関数のことをメソッドという。
関数とは異なり、メソッドはデータの後ろに .メソッド名() とつなげて使用する。
メソッドの使い方を一般的な形で図に表すと、次のようになる。
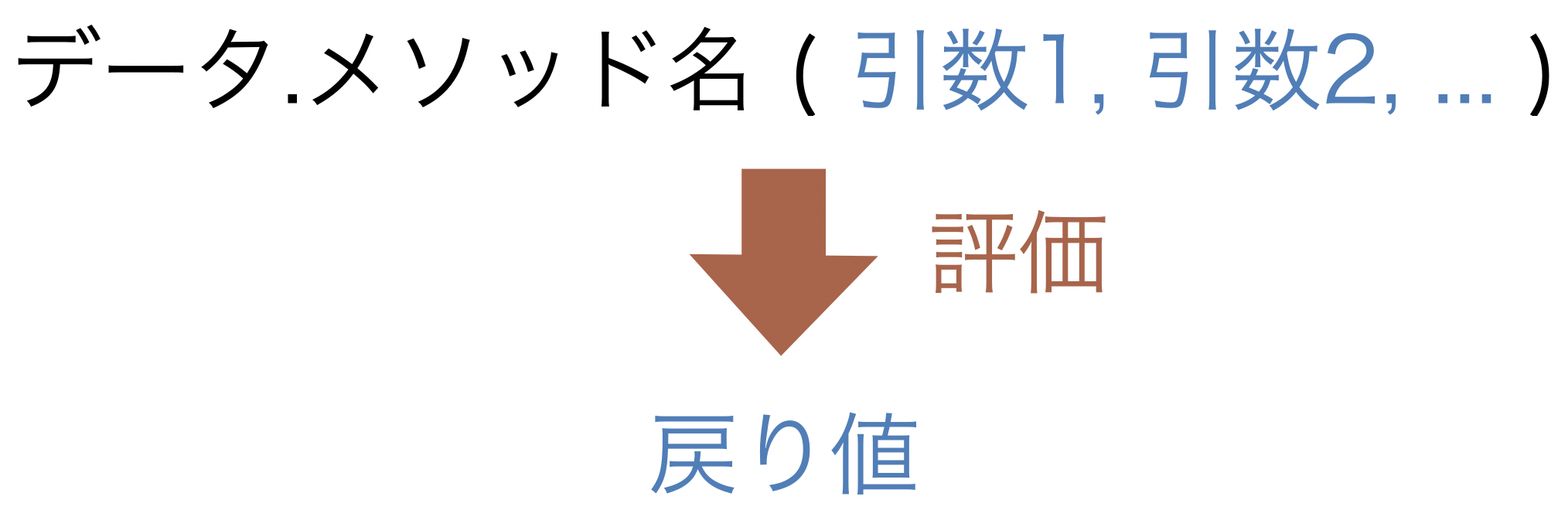
Fig. 7 メソッドの使い方#
例として、文字列型のメソッドである split() を見てみよう。split() は引数に渡した区切り文字をもとに、文字列を区切ってリストとして返す。
s = "Hello, world!"
s.split(",")
['Hello', ' world!']
s = "Mon Tue Wed Thu Fri Sat Sun"
s.split(" ")
['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
メソッドの場合、データ自身は引数に書かなくても自動的にメソッドに渡される。
文字列型のメソッドの他の例として upper() や lower() がある。文字列をそれぞれ大文字と小文字に変換して返すメソッドであり、引数は取らない。引数は取らなくてもデータ自身はメソッドに渡されるため、実質的に引数が1つの関数を実行するようなものである。
s = "Mon Tue Wed Thu Fri Sat Sun"
s.upper()
'MON TUE WED THU FRI SAT SUN'
s = "Mon Tue Wed Thu Fri Sat Sun"
s.lower()
'mon tue wed thu fri sat sun'
リスト型のメソッドの例も挙げておこう。index() メソッドは、引数に渡した値がリストに含まれていれば、その(左読みの)インデックスを返す。含まれていないとエラーになる。
x = [8, 1, 3, 7, 5]
x.index(3)
2
x.index(7)
3
x.index(2)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/var/folders/p0/0zrw9jsj03v3vlszs8v3m2p40000gn/T/ipykernel_74814/3337172969.py in <module>
----> 1 x.index(2)
ValueError: 2 is not in list
さて、データとそれの持つメソッドをまとめたものをオブジェクトという。 オブジェクトは日本語では物という意味である。 Pythonに出てくるほとんど全ての要素はオブジェクトとして作られており、これまで学んできたデータも全てオブジェクトである。 オブジェクトの種類をクラスと呼び、クラスに基づいて作られる具体的なオブジェクトをインスタンスと呼ぶ。 オブジェクトとインスタンスは似ているが、前者はより一般的な概念で、後者は特定のクラスを具体化したものを指す。 またデータ型もクラスの一つである。
ここまでに出てきた概念について、理解を深めるために工作の例え話で説明してみよう。 例えば、木材を加工する状況を考える。 一言に木材といっても、重さや手触りなど1つ1つの木材には個性がある。 今、手にしている木材は、木材という概念を具体化したものであり、木材という概念がクラス、具体化したものがインスタンスにあたる。
木材を加工するときには、例えば木材用のノコギリを使って切ることになるだろう。このノコギリを使って切るという行為は、木材ならば個性に関係なく適用することができるため、メソッドと捉えることができる。 これは木材に特化したメソッドであり、ガラスなど他の物質に適用することはできない。
文字列型について、今の例え話に沿って説明してみよう。文字列 "mikan" および "banana" は異なる値(個性)を持ち、それぞれ文字列クラスのインスタンスである。どちらも文字列に専属の split() メソッドを適用できるが、その結果は値に応じて異なる。
"mikan".split("a")
['mik', 'n']
"banana".split("a")
['b', 'n', 'n', '']
split() は文字列のメソッドであるから、他のクラスのインスタンスには適用できない。
212.split(1)
File "/var/folders/p0/0zrw9jsj03v3vlszs8v3m2p40000gn/T/ipykernel_74814/2250490062.py", line 1
212.split(1)
^
SyntaxError: invalid syntax
演習#
課題1
リスト values と、その中の要素 v を与える。v の values におけるインデックスを出力するプログラムを作成しなさい。
# 以下は、values と v の一例 (この例では3と出力するのが正しい)
values = [5, 4, 3, 2, 1]
v = 2
### 以下を埋めて提出する
print(result)
###
課題2
とある施設の来場者を記録した文字列データ visitors があり、お客さんの苗字が来場した順番に, 区切りで入力されているとする。
来場者の一人の苗字が name として与えられるとき、この人物が何人目の来場者だったかを調べて出力するプログラムを作成しなさい。
# 以下は、visitors と name の一例 (この例では2と出力するのが正しい)
visitors = "Sato,Tanaka,Suzuki,Yamada,Matsumoto"
name = "Tanaka"
### 以下を埋めて提出する
print(result)
###
課題3
課題2と同じ設定において、visitors のデータは来場者が自由に記入したものであるため、大文字と小文字の使い方に一貫性がなかったとする。name については全て小文字で与えるとするとき、name で指定される人物が何人目の来場者だったかを調べて出力するプログラムを作成しなさい。
# 以下は、visitors と name の一例 (この例では3と出力するのが正しい)
visitors = "Sato,tanaka,Suzuki,yamada,Matsumoto"
name = "suzuki"
### 以下を埋めて提出する
print(result)
###