第7回 データ構造#
![]()
この授業で学ぶこと#
第4回の授業で、複数のデータをまとめるためのデータ型としてリスト型を紹介した。 Pythonにはリスト型の他にも、データの入れ物の役割を果たすデータ型がいくつか存在する。 今回はそれらの使い方を学ぶ。
データの入れ物#
リスト型のようにデータの入れ物の役割を果たす組み込み型として、他にも辞書型(dict)、タプル型(tuple)などがある。 はじめのうちはリスト型と辞書型を使いこなすことが重要なので、これらに重点を置きつつ一通り説明する。 リスト型は改めての説明になるが、第4回の内容より一歩踏み込んで学ぶ。
リスト型#
第4回で学んだ通り、リストはデータを , で区切り、両端を [] で囲うことで作成できる。
x = [1, 2, 3, "four", 5]
インデックスによる要素のアクセス方法を復習しておこう。上の例で "four" や 5 を取り出すには、以下のようにインデックスを指定する。
x[3]
'four'
print(x[4])
print(x[-1])
5
5
要素の追加と変更#
今回新たに要素の追加方法を学ぶ。
よく使われるのが要素を末尾に追加する方法で、append() メソッドを用いる。
append() は、引数に渡されたデータをリストの末尾に追加する。
x.append(6)
x
[1, 2, 3, 'four', 5, 6]
要素を特定の位置に挿入するには insert() メソッドを用いる。insert() は、第一引数にインデックス、第二引数にデータを受け取る。
x.insert(0, "zero")
print(x)
x.insert(2, "1/2")
print(x)
['zero', 1, 2, 3, 'four', 5, 6]
['zero', 1, '1/2', 2, 3, 'four', 5, 6]
末尾に他のリストを連結するには extend() メソッドを用いる。 extend() は、引数に渡されたリストを自身の末尾に連結する。
x.extend([7, 8])
x
['zero', 1, '1/2', 2, 3, 'four', 5, 6, 7, 8]
リストの連結は + 演算子によっても実現できる。extend() メソッドと違って、新しいリストが作成されることに注意する。
y = x + [9, 10]
print(y)
print(x) # x自身は変わらない
['zero', 1, '1/2', 2, 3, 'four', 5, 6, 7, 8, 9, 10]
['zero', 1, '1/2', 2, 3, 'four', 5, 6, 7, 8]
代入文により要素を変更することもできる。
x[0] = 0
print(x)
x[3] = '2'
print(x)
[0, 1, '1/2', 2, 3, 'four', 5, 6, 7, 8]
[0, 1, '1/2', '2', 3, 'four', 5, 6, 7, 8]
要素の削除#
要素を削除するにはdel文、または pop() や remove() メソッドを用いる。del文は del の後ろに指定した要素を削除する。あとで説明するスライスと組み合わせると、複数の要素をまとめて削除することもできる。
del x[2]
print(x)
del x[6:] #スライス
print(x)
[0, 1, '2', 3, 'four', 5, 6, 7, 8]
[0, 1, '2', 3, 'four', 5]
pop() メソッドは引数で指定したインデックスの要素をリストから削除し、その値を戻り値として返す。
elem = x.pop(2)
print(elem)
print(x)
2
[0, 1, 3, 'four', 5]
remove() メソッドは引数で指定した値と同じ値の要素を検索し、(複数ある場合は)そのうち一番左の要素を削除する。戻り値はない。
print(x)
x.append("four")
print(x)
x.remove("four")
print(x)
[0, 1, 3, 'four', 5]
[0, 1, 3, 'four', 5, 'four']
[0, 1, 3, 5, 'four']
スライス#
リストに入っている要素のうち、連続した複数の要素を取り出すために用いられるのがスライスである。
整数 i、j を用いてリストに対して [i:j] と要素を指定すると、インデックスについて i から j-1 までの要素を切り出すことができる。
i または j を省略することもできる。
[:j] は、インデックスについて最初から j-1 までの要素を切り出す。
[i:] は、インデックスについてi から最後までの要素を切り出す。
以下にサンプルコードと図を示す。
x = [1, 2, 3, "four", 5]
print(x[1:4])
print(x[:4])
print(x[1:])
[2, 3, 'four']
[1, 2, 3, 'four']
[2, 3, 'four', 5]
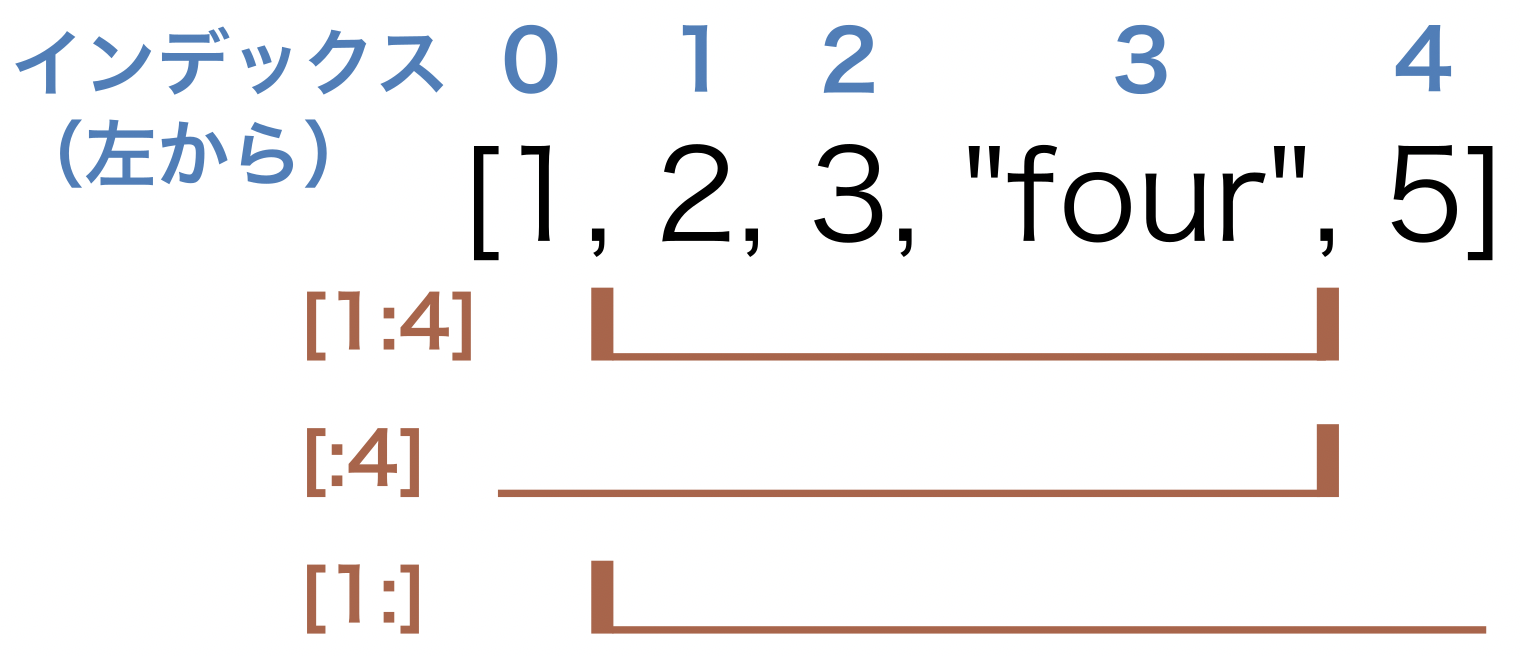
Fig. 16 スライスとインデックスの関係#
練習1
正の整数 n が与えられるとき、for文と append() メソッドを使って1から順に n までの整数を含むリストを作成し、出力しなさい。
# nの一例 (この例では [1, 2, 3, 4] と出力するのが正しい)
n = 4
y = []
for i in range(n):
pass # 適切なコードを書く
print(y)
解答例
y = []
for i in range(n):
y.append(i+1)
print(y)
別解例
y = []
for i in range(1, n+1):
y.append(i)
print(y)
練習2
整数を要素とするリスト x が与えられるとき、そのうち値が偶数の要素のみを取り出して新たなリストを作成し、出力しなさい。
# xの一例 (この例では[2, 4]と出力するのが正しい)
x = [1, 2, 3, 4, 5]
y = []
for v in x:
pass # 適切なコードを書く
print(y)
解答例
y = []
for v in x:
if v % 2 == 0:
y.append(v)
print(y)
練習3
リスト x と整数 i が与えられるとき、リストの要素を i 回だけ右に回転させたリスト y を作成し、出力しなさい。ただし、i は0以上 len(x) 以下とする。
例: リスト [1, 2, 3, 4, 5] を2回回転させると、[4, 5, 1, 2, 3] になる。
# xとiの一例 (この例では[4, 5, 1, 2, 3]と出力するのが正しい)
x = [1, 2, 3, 4, 5]
i = 2
left = x[:] # この2行について、スライスの内容を書き換える
right = x[:]
y = left + right
print(y)
解答例
left = x[-i:] right = x[:-i] y = left + right print(y)
右からi番目以降の要素を left に、右からi番目より前の要素を right に代入する。
右から数えるときは右読みのインデックス(負の値)を使うと簡単である。
辞書型#
リストでは0から始まる整数インデックスをもとに要素にアクセスした。 辞書型は、自由に設定したキー(key)をもとに要素にアクセスできるようにしたデータ型である。 辞書型では要素のことを値(value)と呼ぶ。
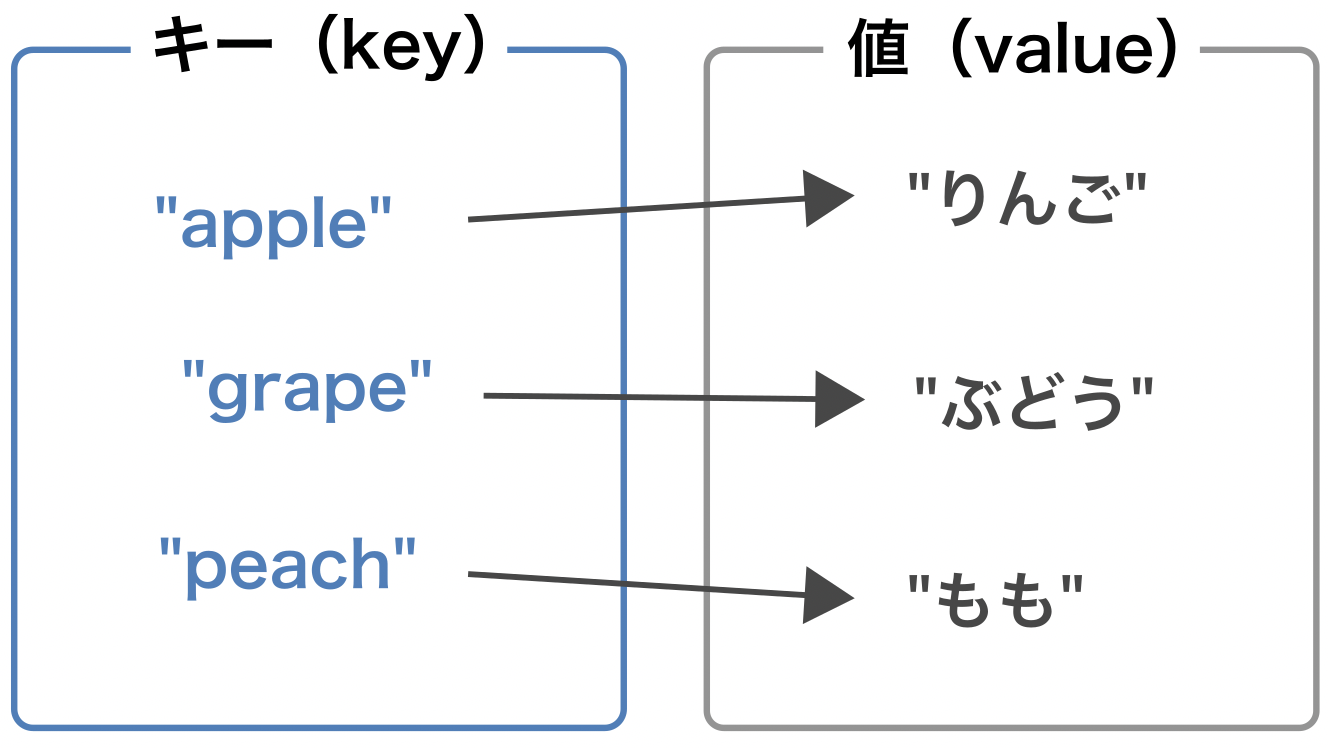
Fig. 17 辞書型#
辞書は、: を使ってキーと値のペアを指定し、各ペアを , で区切って、両端を {} で囲うことで作成できる。
x = {"apple": "りんご", "grape": "ぶどう", "peach": "もも"}
type(x)
dict
リストと同様、値には [] を使ってアクセスできる。
print(x["apple"])
print(x["grape"])
りんご
ぶどう
存在しないキーを指定するとエラーになる。 キーが存在するかは、in演算子により確かめることができる。 したがって、キーが存在するかわからない場合は、if文で確かめてからアクセスすること。
if "cherry" in x:
print(x["cherry"])
else:
print("cherryは存在しないキーです。")
cherryは存在しないキーです。
値にはどのようなデータ型も使用できる。 ただし、キーにはイミュータブル(変更不可能)なデータ型しか使用できない。 これはキーが途中で変わらないことを保証するためである。
発展的な話題: ミュータブルとイミュータブル
値を変更可能なデータ型をミュータブル、変更不可能なデータ型をイミュータブルという。
リストや辞書はミュータブルなデータ型である。実際、それぞれ [] を使った代入文により要素を変更することができる。
一方で、整数、浮動小数点数、文字列、真偽値はイミュータブルなデータ型である。
例えば、次のようなコードを実行したとする。
x = 1 x = 2
このとき x = 2 は、新しいオブジェクト 2 を作成して変数 x に代入しているのであって、元のオブジェクト 1 の値を変更しているわけではない。
これらの区別は、次のような例で重要になる。y = x というコードを実行した時点では、どちらのケースでも x と y は同じオブジェクトを参照している(第3回に説明したように同じオブジェクトに付箋がついているイメージ)。
# ケース1 x = 1 y = x x = 2 print(y) # 出力は1
上の例で x = 2 は新しいオブジェクトを x に代入しているので、変数 y に影響はない。
# ケース2 x = [1, 2] y = x x[0] = 3 print(y) # 出力は[3, 2]
上の例で x[0] = 3 はオブジェクトの要素を変更している。したがって、変数 y の参照する値も変更される!
要素の追加と変更#
辞書に要素を追加したり変更したりするには、代入文を用いる。
x["cherry"] = "さくらんぼ" # 追加するときには、存在しないキーを指定してもエラーにならない
x["grape"] = "ブドウ"
print(x)
{'apple': 'りんご', 'grape': 'ブドウ', 'peach': 'もも', 'cherry': 'さくらんぼ'}
要素の削除#
辞書から要素を削除するには、del文を用いる。
del x["grape"]
print(x)
{'apple': 'りんご', 'peach': 'もも', 'cherry': 'さくらんぼ'}
ループ処理#
リストと同様、辞書の中身を一つずつ取り出して何らかの処理を行う機会は多い。 辞書型では、for文を使って次のようにループ処理を行う。
for key in x: # keyにはキーが順に代入される
print(f"{key}: {x[key]}")
apple: りんご
peach: もも
cherry: さくらんぼ
練習4
以下の辞書 x について、全ての値を1増やすコードを作成しなさい。具体的に x['a'] などとアクセスしてよい。
x = {'a': 0, 'b': 1, 'c': 2}
解答例
x['a'] += 1 x['b'] += 1 x['c'] += 1
練習5
'a'、'b'、'c' から成るリスト data が与えられる。辞書を使って 'a'、'b'、'c' の出現回数をカウントし、結果を出力しなさい。
# dataの一例 (この例では{'a': 3, 'b': 2, 'c': 1}と出力するのが正しい)
data = ['a', 'b', 'a', 'a', 'c', 'b']
count = {'a': 0, 'b': 0, 'c': 0}
for c in data:
pass # 適切なコードを書く
print(count)
解答例
count = {'a': 0, 'b': 0, 'c': 0}
for c in data:
count[c] += 1
print(count)
c には data の要素('a' または 'b' または 'c')が順に代入される。
その度に、辞書 count の c の値を1増やせばよい。
練習6
小文字のアルファベットから成るリスト data が与えられる。辞書を使ってそれぞれの文字の出現回数をカウントし、結果を出力しなさい。
練習1とは違って、辞書の中身は与えていないので工夫すること。
# dataの一例 (この例では{'a': 3, 'e': 2, 'f': 1}と出力するのが正しい)
data = ['a', 'e', 'a', 'a', 'f', 'e']
count = {}
for c in data:
pass # 適切なコードを書く
print(count)
解答例
count = {}
for c in data:
if c in count:
count[c] += 1
else:
count[c] = 1
print(count)
基本的に練習5と同じであるが、今回は count が空なので、初めて出てきた文字について += 1 を実行しようとするとエラーになる。
そこでin演算子により count にキーが存在するかを確認し、存在する場合は +=1 を実行し、存在しない場合は初めて出てきた文字であることがわかるので =1 によりキーと値を初期設定する。
タプル型#
タプル型は、リスト型をイミュータブルにしたデータ型である。データを , で区切り、両端を () で囲うことで作成できる。
リストと異なる点として、要素数が1つの場合も (2,) のように , で終わる必要がある。
a = (1, 2, 3, 4, 5)
b = (2,)
type(b)
tuple
c = (2) #これは2と同じ
type(c)
int
要素のアクセス方法は、リストと同じである。
print(a[2])
print(a[4])
print(a[-1])
3
5
5
イミュータブルなデータ型なので、値を変更しようとするとエラーになる。
a[2] = "two"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/p0/0zrw9jsj03v3vlszs8v3m2p40000gn/T/ipykernel_27880/1129163381.py in <module>
----> 1 a[2] = "two"
TypeError: 'tuple' object does not support item assignment
タプルのリストにない利点として、例えば辞書のキーとして使える点が挙げられる。
x = {(5,3): 15, (2,4): 8}
x = {[5,3]: 15, [2,4]: 8} # リストはミュータブルなので、キーとして使用できない
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/p0/0zrw9jsj03v3vlszs8v3m2p40000gn/T/ipykernel_27880/3156722867.py in <module>
----> 1 x = {[5,3]: 15, [2,4]: 8} # リストはミュータブルなので、キーとして使用できない
TypeError: unhashable type: 'list'
演習#
『不思議の国のアリス』のテキストを使って、アルファベットの出現頻度を調べてみよう。
以下のコードを実行することで、文章を単語ごとに分割して作成されたリストが alice に代入される。
import nltk
nltk.download('gutenberg')
alice = nltk.text.Text(nltk.corpus.gutenberg.words('carroll-alice.txt'))
alice の最初の20個の要素は次の通りである。
alice[:20]
['[',
'Alice',
"'",
's',
'Adventures',
'in',
'Wonderland',
'by',
'Lewis',
'Carroll',
'1865',
']',
'CHAPTER',
'I',
'.',
'Down',
'the',
'Rabbit',
'-',
'Hole']
課題1
alice のリストにおける "Alice" の出現回数を調べて出力するプログラムを作成しなさい。この課題では、大文字と小文字を区別すること。
count = 0
for word in alice:
pass # 適切なコードを書く
print(count)
課題2
小文字のアルファベット char が与えられるとき、alice の全単語における char の出現回数を調べて出力するプログラムを作成しなさい。ただし、大文字と小文字は区別せずに数えること。
# charの一例
char = "a"
count = 0
for word in alice:
for c in word:
c = c.lower() # 大文字は小文字に直しておく
pass # 適切なコードを書く
print(count)
課題3
alice の全単語における各アルファベットの出現回数を調べて、出現回数の多い上位10個を出力するプログラムを作成しなさい。ただし、大文字と小文字は区別せずに数えること。以下のコード中に、アルファベットをキー、出現回数を値とする辞書 dic を作成するコードを追加することで、題意のプログラムが完成する。
ヒント: 出現回数が最も多いのは “e”
dic = {}
for word in alice:
for c in word:
c = c.lower() # 大文字は小文字に直しておく
if not ('a' <= c and c <= 'z'): # cがアルファベット以外の場合はスキップする
continue
# ここに適切なコードを書く
# 辞書の値に基づいてキーを並び替え、上位10個を取得
sorted_keys = sorted(dic, key=dic.get, reverse=True)[:10]
# 上位10個のキーを表示
print(sorted_keys)