第6回 繰り返し#
![]()
この授業で学ぶこと#
プログラムの実行順序を制御する構文の中で、最も基本的なものが条件分岐と繰り返しである。前回は条件分岐について学んだが、今回はもう片方の繰り返しについて学ぶ。
for文とwhile文#
0 から n-1 までの数字を順に出力するプログラムを書いてみよう。これはfor文を用いることで次のように実現できる。
n = 5
for i in range(n):
print(i)
0
1
2
3
4
for文の書き方について解説する。上のコードを図で表すと次のようになる。

Fig. 10 for文の書き方#
イテラブルオブジェクトとは「繰り返すことが可能なオブジェクト」という意味である。 この名前は、繰り返す(iterate)ことが可能という意味の形容詞であるiterableに由来する。
range() 関数はイテラブルオブジェクトを生成する関数であり、range(n) により生成されるオブジェクトは 0 から n-1 までの n 個の整数を順に生成する。
for i in range(n) という構文により、これらの整数が順に変数 i に代入され、代入される度にブロックのコードが実行される。
文字列やリストもイテラブルオブジェクトである。文字列の場合は1文字ずつ、リストの場合は1要素ずつ変数に代入される。
for c in "text": # cはcharacterの頭文字
print(c)
t
e
x
t
for v in [2, 3, 4, 5]: # vはvalueの頭文字(他にi, x, elem, itemなどがよく使われる)
print(v)
2
3
4
5
for文に用いる変数名は自由に決めてよいが、一般的に短くて分かりやすく、代入されるデータを端的に表すものが好まれる。
例えば文字が代入される場合には、慣例として c や char が使われることが多い。
ただし、慣例は人それぞれなので、最初はそれほど気にする必要はない。
例えば、リストの要素の平均値を求めるコードは次のように書ける。
total = 0
data = [2, 3, 4, 5]
for v in data:
total += v
mean = total / len(data)
print(mean)
3.5
同じことを range() 関数でインデックスを生成することにより行うこともできる。
total = 0
data = [2, 3, 4, 5]
for i in range(len(data)): # iはindexの頭文字
total += data[i]
mean = total / len(data)
print(mean)
3.5
練習1
(1) リスト data の要素を前から順に出力するプログラムを作成しなさい。ここでは、range() 関数でインデックスを生成する方法を利用すること。
# dataの一例
data = ['H', 'e', 'l', 'l', 'o']
### 以下を埋める。どのようなdataが与えられても正しく動くように書くこと。
###
解答例
for i in range(len(data)):
print(data[i])
(2) リスト data の要素を後ろから順に出力するプログラムを作成しなさい。
# dataの一例
data = ['o', 'l', 'l', 'e', 'H']
解答例
for i in range(len(data)):
j = len(data)-i-1
print(data[j])
例えば data = ['o', 'l', 'l', 'e', 'H'] の場合、変数 i には順に 0、1、2、3、4 が代入されるが、それぞれに対して変数 j の値は 4、3、2、1、0 となる(len(data) は5より)。
よって、data[j] により data の要素を後ろから順に取り出すことができる。
for文の他にwhile文も繰り返し処理を行うための構文である。 リストの要素の平均値を求めるプログラムは、while文を使って次のように書くこともできる。
i = 0
total = 0
data = [2, 3, 4, 5]
while i < len(data):
total += data[i]
i += 1
mean = total / len(data)
print(mean)
3.5
while文の書き方について解説する。上のコードを図で表すと次のようになる。

Fig. 11 while文の書き方#
while文では、条件式が真であるかを判定し、真であればブロックを実行するという処理を、条件式が初めて偽になるまで繰り返し行う。 したがって、適切に条件式を設定しないと無限ループに陥る可能性がある。 また、初めから条件式が偽の場合は、ブロックは一度も実行されない。
平均値を求める例では、繰り返しの度にインデックスを表す変数 i の値を1つずつ増やし、i がリストのインデックスの範囲を超えたところで条件式が偽となるように設定している。
文のネスト#
これまでに学んだif文、for文、while文は、それぞれ内側のブロックに入れ子的に使用することができる。 このような入れ子構造のことをネストという。
特にfor文にfor文をネストさせたものを二重ループという。 二重ループの例を次に示す。
for i in range(1, 5):
for j in range(1, 4):
print(f"{i} * {j} は {i * j} です。")
1 * 1 は 1 です。
1 * 2 は 2 です。
1 * 3 は 3 です。
2 * 1 は 2 です。
2 * 2 は 4 です。
2 * 3 は 6 です。
3 * 1 は 3 です。
3 * 2 は 6 です。
3 * 3 は 9 です。
4 * 1 は 4 です。
4 * 2 は 8 です。
4 * 3 は 12 です。
range(a, b) により生成されるイテラブルオブジェクトは、a から b-1 までの整数を順に生成する。上の例では、変数 i に1から4までの整数が順に代入され、それぞれの場合に変数 j に1から3までの整数が順に代入される。したがって、合わせて12回 print() が実行される。
練習2
二重ループにおいて一番内側のブロックを実行する度に、それが何回目の処理かを出力するプログラムを作成しなさい。
count = 0
for i in range(3):
for j in range(3):
pass # ここにcountを使ったコードを書く
解答例
count = 0
for i in range(3):
for j in range(3):
count += 1
print(count)
pass
pass は何もしないという意味の文である。構文上、何か書かないとエラーになるが、コードの作成は後回しにしたい箇所に置いておく。テキストでも何度か登場するが、コードを書くときに消してしまって問題ない。
break文とcontinue文#
繰り返しの途中でfor文やwhile文を抜けたり、次の繰り返しまでスキップしたりする処理を書きたくなることがある。 そのようなときに用いられるのが、break文やcontinue文である。
これらの文の意味は、for文とwhile文のどちらで使われても変わらないので、ここではwhile文を例に説明しよう。 break文もcontinue文も、ほとんどの場合、if文と組み合わせて用いられる。 以下にbreak文とcontinue文を使ったプログラム例を示す。
# break文
i = 0
while i < 5:
i += 1
print("処理1")
if i == 3:
break
print("処理2")
print(i)
処理1
処理2
1
処理1
処理2
2
処理1
# continue文
i = 0
while i < 5:
i += 1
print("処理1")
if i == 3:
continue
print("処理2")
print(i)
処理1
処理2
1
処理1
処理2
2
処理1
処理1
処理2
4
処理1
処理2
5
break文に到達すると、そこでwhile文の処理を終了する。
1つ目の例では、その結果として、i==3 のときに 処理1 と出力したあと全体の処理が終了している。
continue文に到達すると、ブロックの残りのコードを実行せず、次の繰り返しに入る。
2つ目の例では、その結果として、i==3 のときに 処理2 や i の出力が行われていない。
break文とcontinue文それぞれについて、実行の流れをフローチャートで表現すると次のようになる。
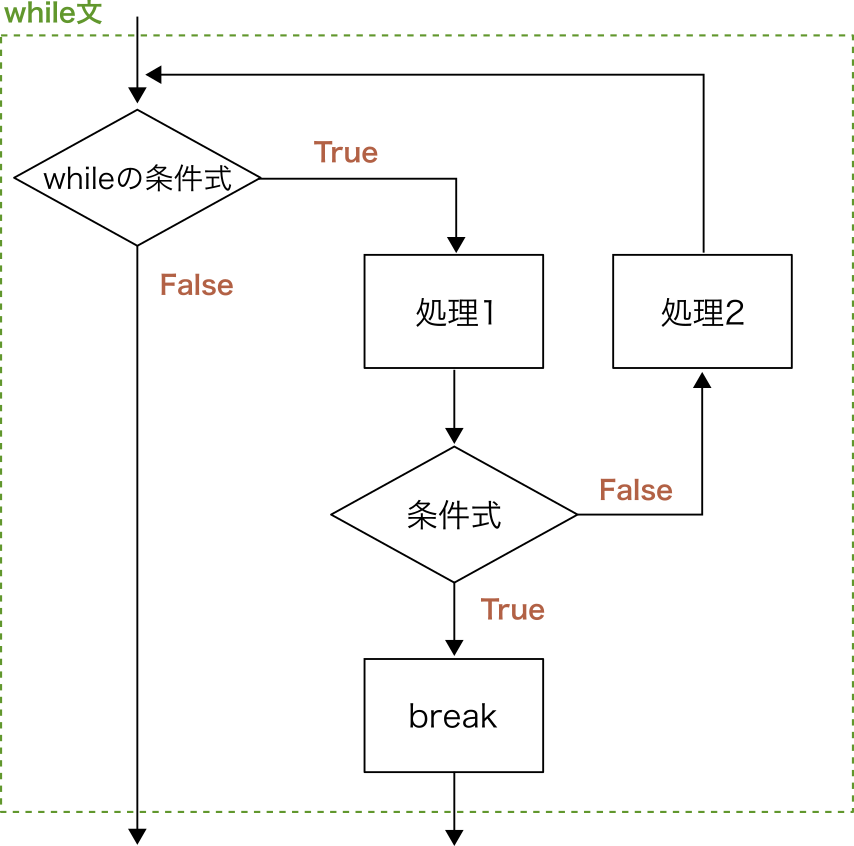
Fig. 12 break文のフローチャート#
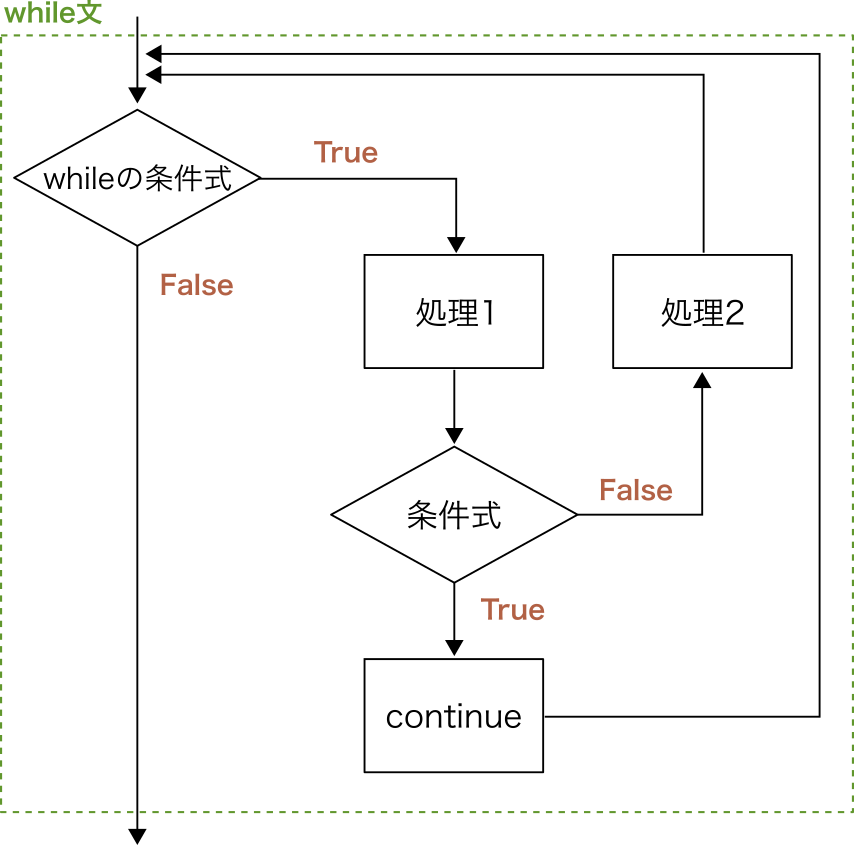
Fig. 13 continue文のフローチャート#
インデントとブロックの関係#
次の3つのコードは、末尾2行のインデントの大きさが異なる。 それぞれの場合に、末尾2行のコードはどのタイミングで実行されるかわかるだろうか。

Fig. 14 インデントの違い#
答えを書くと一番左の例では、末尾2行のコードはどのブロックにも属さないため、while文を抜けたあとに実行される。
真ん中の例では、末尾2行のコードはwhile文のブロックに属するため、while文のループごとに実行される。
一番右の例では、末尾2行のコードはif文のブロックに属する。そのため実行されるとしたらwhile文のループ中 i == 3 のときのみであるが、if文のブロックにあるbreak文でwhile文を抜けてしまうため、末尾2行のコードが実行されることはない。
それぞれのコードにおいて、while文のブロックを黄色、if文のブロックを青色のハイライトで可視化すると次の図のようになる。

Fig. 15 インデントとブロックの関係#
このように同じインデントレベルの行は、同じブロックを形成する。 インデントが深くなると新しいブロックが開始する。 そしてインデントが元に戻ると現在のブロックが終了し、元のブロックが再開される。
二次元リスト#
リストを要素に持たないリストのことを一次元リストという。 すべての要素が一次元リストであるリストのことを二次元リストという。 この授業で二次元リストと言ったときは、要素の一次元リストのサイズは揃っているものとする。
二次元リストの例を次に示す。二次元リストの場合は2つのインデックスを使って(一番内側の)要素にアクセスする。
# インデックスと要素の関係
data = [[1, 2], [3, 4], [5, 6]]
print(data)
print(data[0])
print(data[0][0])
print(data[2][1])
[[1, 2], [3, 4], [5, 6]]
[1, 2]
1
6
二次元リストの全ての要素の合計値は、二重ループを使って次のように求められる。変数 l、v にどのような値が代入されているか示すため、逐一 print() を行っている。
total = 0
for l in data:
print(f"l = {l}")
for v in l:
print(f"v = {v}")
total += v
print(total)
l = [1, 2]
v = 1
v = 2
l = [3, 4]
v = 3
v = 4
l = [5, 6]
v = 5
v = 6
21
for l in data により、リストの要素であるリスト [1, 2]、[3, 4]、[5, 6] が順に変数 l に代入される。
さらに for v in l により、各リスト l から要素である数値が順に変数 v に代入される。
同じことを range() 関数でインデックスを生成することにより行うこともできる。
total = 0
for i in range(len(data)):
for j in range(len(data[i])):
total += data[i][j]
print(total)
21
練習3
要素が数値の二次元リスト data を与える。data の全ての要素の平均値を求めて出力するプログラムを作成しなさい。ただし、data は少なくとも1つ数値を含むとしてよい(つまり data = [[]] というケースはない)。
# dataの一例 (この例では5と出力するのが正しい)
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
### 以下を埋める。
# どのようなdataが与えられても正しく動くように書くこと。またprint()関数を使うこと。
###
解答例
total = 0
count = 0
for l in data:
for v in l:
total += v
count += 1
print(total / count)
上記のように書くと、total には全ての要素の合計値が、count には要素数が入った状態になる。
よって、total / count により平均値が求まる。
NumPy
NumPyは、数値計算を効率的に行うためのライブラリである。
講義の後半でMatplotlibやPandasといったライブラリを学ぶ際に利用することになるので、ここで簡単に紹介しておく。
NumPyでは ndarray (配列)というデータ型を主に用いる。
ndarray は、np.array() 関数にリストを渡すことで、生成することができる。
import numpy as np data = np.array([[1, 2], [3, 4], [5, 6]])
この例では二次元リストを渡して、二次元配列を生成している。基本的な扱い方は、リストと同じである。
異なる点を2つ紹介する。
1つ目として、インデックスによる要素のアクセス方法がある。二次元リストでは、data[i][j] というように [] を重ねて要素を指定したが、二次元配列では、data[i,j] のように , 区切りで要素を指定する。data[i,j] と指定するときの i を行、j を列という。
print(data[2,1]) # 出力は6
2つ目として、配列には各種演算が定義されており、要素ごとの演算を一括で行える点がある。
data = np.array([1, 2, 8]) print(data + 1) # 出力は [2, 3, 9] print(data * 2) # 出力は [2, 4, 16] print(np.log2(data)) # 出力は [0, 1, 3] data = [1, 2, 8] print(data + 1) # リストではエラー
演習#
課題1
for文を使って、1から30までの整数について、3で割り切れる数は "Fizz"、5で割り切れる数は "Buzz"、15で割り切れる数は "FizzBuzz" に置き換えて出力し、それ以外の数はそのまま出力するプログラムを作成しなさい。これは英語圏で有名な言葉遊びである。
ヒント: 3で割り切れるは、3で割った余りが0ということ(if文と%演算子を使う)
for i in range(1, 31):
pass # ここに適切なコードを書く
課題2
1以上の整数 v が与えられるとき、以下の手順に沿って整数を変換し、その度に出力するプログラムを作成しなさい。
数字が偶数の場合、2で割る
数字が奇数の場合、3をかけて1を足す
数字が1になったら終了する
例えば v = 12 の場合、出力は 6, 3, 10, 5, 16, 8, 4, 2, 1 になる。
ちなみに、どんな整数から始めても必ず1に到達すると予想されているが、証明はまだない(コラッツ予想)。正しいことを証明するか、反例を1つでも見つければおよそ1億円の懸賞金がもらえるそうである(記事)。
# vの一例
v = 12
while True:
# ここに変換処理を書く
print(v)
# ここに v == 1 のとき break すると書く